قطار بمقابله ڪالمن (هڪ فرق آهي!) - سڀ فرق


مواد جي جدول
ڪجهه تحقيق ڪرڻ ڪو سولو ڪم ناهي. توهان کي ڊيٽا گڏ ڪرڻ لاءِ سوين ذريعن جو انٽرويو ڪرڻ جي ضرورت آهي، ۽ پوءِ ان جي ذريعي ترتيب ڏيڻ شروع ڪرڻ لاءِ صاف طريقي سان ڊيٽا جي وڏي مقدار کي گروپ ڪريو.
پر توهان پنهنجي قيمتي ڊيٽا کي ڪيئن گڏ ڪندا؟ جواب آهي: ٽيبل ذريعي.
شيء اها آهي ته، ماڻهو اڪثر ڪري قطار ۽ ڪالمن جي وچ ۾ پريشان ٿي ويندا آهن جڏهن ٽيبل ٺاهڻ. ڪالمن ۽ قطارون MS Excel ۽ ٻين سافٽ ويئر ۾ پڻ استعمال ٿين ٿيون جيڪي اسان عام طور تي هر روز استعمال ڪندا آهيون.
تنهنڪري، هي آرٽيڪل توهان کي ٻنهي جي وچ ۾ فرق ڪرڻ ۾ مدد ڪندو.
ڊيٽا ڇا آهي؟
ان کان اڳ جو اسان شروع ڪريون، اهو ضروري آهي ته پهرين ڊيٽا ۽ معلومات جي وچ ۾ فرق کي سمجھو. جڏهن ته اهي عام طور تي هڪ ٻئي سان استعمال ٿيندا آهن، اهي مختلف شين ڏانهن اشارو ڪندا آهن.
ڊيٽا هڪ شخص، جڳهه، يا رجحان بابت گڏ ڪيل خام حقيقتن ڏانهن اشارو ڪري ٿو. اهو مخصوص نه آهي ۽ تمام ننگا آهي. ان کان علاوه، محقق تسليم ڪن ٿا ته انهن جي گڏ ڪيل ڊيٽا جو وڏو حصو غير لاڳاپيل يا بيڪار ٿي سگهي ٿو.
پوء ڪيئن محقق ڊيٽا گڏ ڪندا؟
خير، ڊيٽا گڏ ڪئي ويندي آهي اڳئين رڪارڊ تي وڃڻ سان، گڏو گڏ محقق جا پنهنجا مشاهدا.
ڊيٽا گڏ ڪرڻ جو سڀ کان وڌيڪ ڪارائتو طريقو آهي تجربو ڪرڻ ، ڪنهن مفروضي (يا نظريي) جي صحيحيت کي جانچڻ لاءِ.
محقق ٻن قسمن جي ڊيٽا تي ڌيان ڏين ٿا:
- 4>پرائمري ڊيٽا (ڪافي، مقداري)
- ثانوي ڊيٽا(اندروني، بيروني)
مطالعن جي مطابق، ابتدائي ڊيٽا جي حوالي ڪيو ويو آهي “ڊيٽا جيڪا ٺاهي وئي آهي محقق، سروي، انٽرويو، تجربن، خاص طور تي هٿ ۾ تحقيق جي مسئلي کي سمجهڻ ۽ حل ڪرڻ لاءِ ٺهيل آهي .”
جڏهن ته ثانوي ڊيٽا آهي “موجوده ڊيٽا ٺاهيل وڏي سرڪاري ادارن، صحت جون سهولتون وغيره. تنظيمي رڪارڊ رکڻ جو حصو.”
معياري ڊيٽا مجرد ڊيٽا ڏانهن اشارو ڪري ٿو، مطلب ته ڊيٽا جهڙوڪ پسنديده رنگ، ڀائرن جو تعداد، ۽ رهائش جو ملڪ. ٻئي طرف، مقداري ڊيٽا ڏانهن اشارو ڪيو ويو آهي مسلسل ڊيٽا ، جهڙوڪ قد، وار جي ڊيگهه، ۽ وزن.
ڄاڻ ڇا آهي؟
معلومات هڪ شخص، جڳهه، يا واقعن بابت ثابت ڪيل حقيقتن ڏانهن اشارو ڪري ٿو ۽ ڊيٽا کي پروسيسنگ ۽ تجزيو ڪندي حاصل ڪيو وڃي ٿو ڪنيڪشن يا رجحانات ڳولڻ لاء.
هڪ آخري فرق ٻنهي جي وچ ۾ اهو آهي ته ڊيٽا غير منظم آهي، جڏهن ته معلومات ترتيب ڏنل آهي جدولن ۾.
انفارميشن جا چار مکيه قسم آهن:
- <9 حقيقي - معلومات جيڪا صرف حقيقتن کي استعمال ڪندي آهي
- تجزيي - اها معلومات جيڪا حقيقتن جو تجزيو ۽ وضاحت ڪري ٿي
- موضوع - ڄاڻ جيڪو هڪ نقطه نظر سان سلهاڙيل آهي
- مقصد - اها معلومات جيڪا ڪيترن ئي نقطه نظر ۽ نظرين تي ٻڌل آهي
گڏيل ڊيٽا جي بنياد تي، حاصل ڪيل معلومات جو قسمتبديل ٿي ويندا.
قطارون VS ڪالمن
ھي آھن ڪھڙي ريت قطارون ۽ ڪالم نظر اچن ٿا!
قطارون ڇا آھن؟
ڊيٽا پيش ڪرڻ لاءِ قطارن ۽ ڪالمن جو استعمال ضروري آهي. قطار ۽ ڪالمن ۾ ڊيٽا کي ترتيب ڏيڻ سان، هڪ محقق انهن جي ڊيٽا ۾ امڪاني ڪنيڪشن جو مشاهدو ڪري سگهي ٿو، انهي سان گڏ ان کي وڌيڪ پيش ڪرڻ جي قابل بڻائي ٿو.
پر قطارون ۽ ڪالم اصل ۾ ڇا آهن؟
قطار هڪ ٽيبل ۾ افقي ليڪن ڏانهن اشارو ڪن ٿا، جيڪي کاٻي کان ساڄي طرف هلن ٿيون، انهن جي مٿو ۽ کاٻي پاسي کان ٽيبل.
توهان هڪ قطار کي هڪ لڪير وانگر تصوير ڪري سگهو ٿا جيڪا افقي طور تي هڪ ڪمري کان ٻئي تائين پکڙيل هجي، يا ايستائين جو فلم ٿيٽر ۾ سيٽن وانگر جيڪي هال جي هڪ سر کان ٻئي تائين وڃن ٿيون.
فرض ڪريو توهان کي پنهنجي پاڙي ۾ ماڻهن جي عمرن جي فهرست ڏيڻ جي ضرورت آهي. توھان ھي لکندا ھيئن:
| عمر (سال) | 20>1624 | 33 | 50 | 58 |
ڊيٽا نموني جون قطارون
هن ۾ صورت ۾، "عمر" قطار جي سر جي طور تي ڪم ڪري ٿو، جڏهن ته ڊيٽا کاٻي کان ساڄي تائين پڙهي ويندي آهي.
قطارون MS Excel ۾ پڻ استعمال ٿين ٿيون. هتي 104,576 قطارون موجود آهن، جيڪي اميد آهي ته توهان جي سڀني ڊيٽا کي شامل ڪرڻ لاء ڪافي آهن، ۽ اهي سڀئي قطارون نمبرن سان ليبل ٿيل آهن.
قطار جا ٻيا ڪم به آهن.
4اڪيلو ماڻهو.
ڪالم ڇا آهن؟
ڪالمن هڪ ٽيبل ۾ عمودي لائينن ڏانهن اشارو ڪن ٿا، جيڪي مٿي کان هيٺ تائين هلن ٿيون. ڪالم جي وضاحت ڪئي وئي آهي حقيقتن، انگن اکرن، يا ڪنهن ٻئي تفصيل جي عمودي ڊويزن جي درجي جي بنياد تي.
هڪ ٽيبل ۾، ڪالمن کي قطارن سان ورهايو ويو آهي ته جيئن پڙهندڙن کي آسانيءَ سان ذڪر ڪيل ڊيٽا ذريعي ترتيب ڏئي سگهجي. .
فرض ڪيو ته اسان ڪالمن کي مٿين قطار ۾ شامل ڪريون ٿا:
| عمر (سال) | |||
| 16 | |||
| 24 | |||
| 50 | |||
| 58 |

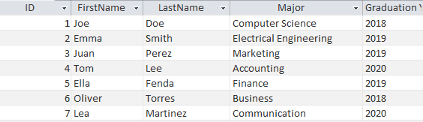
| سيريل نمبر | نالو | عمر (سال) 19> | پسند جو رنگ |
| 1 | لوسي | 12 | 18>بلو|
| 2 | جيمز | 14 | گري |
ڊيٽا پريزنٽيشن جو نمونو
هيڊنگ ڪالمن لاءِ آهن، جڏهن ته ذيلي عنوان قطارن لاءِ آهن. ٽيبلوليشن جو طريقو ناقابل يقين حد تائين مفيد آهي، ڇاڪاڻ ته اهو لاڳاپيل ڊيٽا کي گڏ ڪري ٿو، اهڙيء طرح شمارياتي تجزيي ۽ تشريح ۾ مدد ڪري ٿو. معلومات کي سمجھڻ آسان بڻائي. هاڻي ته اسان قطار ۽ ڪالمن جي وچ ۾ فرق ڄاڻون ٿا، اهو ضروري آهي ته انهن جي مطابق اسپريڊ شيٽ ۾ استعمال ڪيو وڃي.
قطار ۽ ڪالمن جو استعمال آسان بڻائي ٿو معلومات کي افقي ۽ عمودي طور تي اسپريڊ شيٽ ۾ سيلز جي سيريز ۾ رکڻ.
وڌيڪ، اهي قطارون ۽ ڪالم پڻ اهم ڪردار ادا ڪن ٿا ميٽرڪس ۽ ٻين مختلف ڊيٽا ۾گڏ ڪرڻ جون سرگرميون.
ڏسو_ پڻ: وچ ۾ فرق ”ڇا توھان مھرباني ڪري سگھوٿا“ ۽ ”ڇا توھان مھرباني ڪري سگھوٿا“ - سڀ فرقتنهنڪري، قطارن ۽ ڪالمن جو استعمال ضروري آهي ته انهن زمرن کي مڃڻ ۽ ڊيٽا گڏ ڪرڻ لاءِ.
ساڳيا مضمون:
هن آرٽيڪل جي ويب ڪهاڻي ڏسڻ لاءِ هتي ڪلڪ ڪريو.